Learning how to analyze data can be frustrating at times. Why do statistical software companies have to add to our confusion?
I do not have a good answer to that question. What I will do is show examples. In upcoming blog posts, I will explain what each output means and how they are used in a model.
We will focus on ANOVA and linear regression models using SPSS and Stata software. As you will see, the biggest differences are not across software, but across procedures in the same software.
(more…)
 Choosing statistical software is part of The Fundamentals of Statistical Skill and is necessary to learning a second software (something we recommend to anyone progressing from Stage 2 to Stage 3 and beyond).
Choosing statistical software is part of The Fundamentals of Statistical Skill and is necessary to learning a second software (something we recommend to anyone progressing from Stage 2 to Stage 3 and beyond).
You have many choices for software to analyze your data: R, SAS, SPSS, and Stata, among others. They are all quite good, but each has its own unique strengths and weaknesses.
(more…)
In a previous post we discussed using marginal means to explain an interaction to a non-statistical audience. The output from a linear regression model can be a bit confusing. This is the model that was shown.
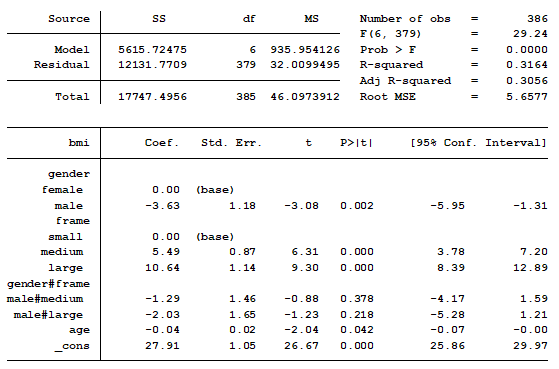
In this model, BMI is the outcome variable and there are three predictors:
(more…)
We’ve talked a lot around here about the reasons to use syntax — not only menus — in your statistical analyses.
Regardless of which software you use, the syntax file is pretty much always a text file. This is true for R, SPSS, SAS, Stata — just about all of them.
This is important because it means you can use an unlikely tool to help you code: Microsoft Word.
I know what you’re thinking. Word? Really?
Yep, it’s true. Essentially it’s because Word has much better Search-and-Replace options than your stat software’s editor.
Here are a couple features of Word’s search-and-replace that I use to help me code faster:
(more…)
In a previous post we discussed the difficulties of spotting meaningful information when we work with a large panel data set.
Observing the data collapsed into groups, such as quartiles or deciles, is one approach to tackling this challenging task. We showed how this can be easily done in Stata using just 10 lines of code.
As promised, we will now show you how to graph the collapsed data. (more…)
Panel data provides us with observations over several time periods per subject. In this first of two blog posts, I’ll walk you through the process. (Stick with me here. In Part 2, I’ll show you the graph, I promise.)
The challenge is that some of these data sets are massive. For example, if we’ve collected data on 100,000 individuals over 15 time periods, then that means we have 1.5 million cells of information.
So how can we look through this massive amount of data and observe trends over the time periods that we have tracked? (more…)