The linear model normality assumption, along with constant variance assumption, is quite robust to departures. That means that even if the 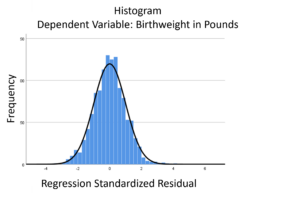 assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
This is great because it gives you a bit of leeway to run linear models, which are intuitive and (relatively) straightforward. This is true for both linear regression and ANOVA.
You do need to check the assumptions anyway, though. You can’t just claim robustness and not check. Why? Because some departures are so far off that the p-values and confidence intervals become inaccurate. And in many cases there are remedial measures you can take to turn non-normal residuals into normal ones.
But sometimes you can’t.
Sometimes it’s because the dependent variable just isn’t appropriate for a linear model. The (more…)
When your dependent variable is not continuous, unbounded, and measured on  an interval or ratio scale, linear models don’t fit. The data just will not meet the assumptions of linear models. But there’s good news, other models exist for many types of dependent variables.
an interval or ratio scale, linear models don’t fit. The data just will not meet the assumptions of linear models. But there’s good news, other models exist for many types of dependent variables.
Today I’m going to go into more detail about 6 common types of dependent variables that are either discrete, bounded, or measured on a nominal or ordinal scale and the tests that work for them instead. Some are all of these.
(more…)
 Effect size statistics are required by most journals and committees these days — for good reason.
Effect size statistics are required by most journals and committees these days — for good reason.
They communicate just how big the effects are in your statistical results — something p-values can’t do.
But they’re only useful if you can choose the most appropriate one and if you can interpret it.
This can be hard in even simple statistical tests. But once you get into complicated models, it’s a whole new story. (more…)
Statistics is, to a large extent, a science of comparison. You are trying to test whether one group is bigger, faster, or smarter than another.
You do this by setting up a null hypothesis that your two groups have equal means or proportions and an alternative hypothesis that one group is “better” than the other. The test has interesting results only when the data you collect ends up rejecting the null hypothesis.
But there are times when the interesting research question you’re asking is not about whether one group is better than the other, but whether the two groups are equivalent.
(more…)
by Annette Gerritsen, Ph.D.
In an earlier article I discussed how to do a cross-tabulation in SPSS. But what if you do not have a data set with the values of the two variables of interest?
For example, if you do a critical appraisal of a published study and only have proportions and denominators.
In this article it will be demonstrated how SPSS can come up with a cross table and do a Chi-square test in both situations. And you will see that the results are exactly the same.
‘Normal’ dataset
If you want to test if there is an association between two nominal variables, you do a Chi-square test.
In SPSS you just indicate that one variable (the independent one) should come in the row, (more…)
The assumptions of normality and constant variance in a linear model (both OLS regression and ANOVA) are quite robust to departures. That means that even if the assumptions aren’t met perfectly, the resulting p-values will still be reasonable estimates.
But you need to check the assumptions anyway, because some departures are so far off that the p-values become inaccurate. And in many cases there are remedial measures you can take to turn non-normal residuals into normal ones.
But sometimes you can’t.
Sometimes it’s because the dependent variable just isn’t appropriate for a linear model. The (more…)
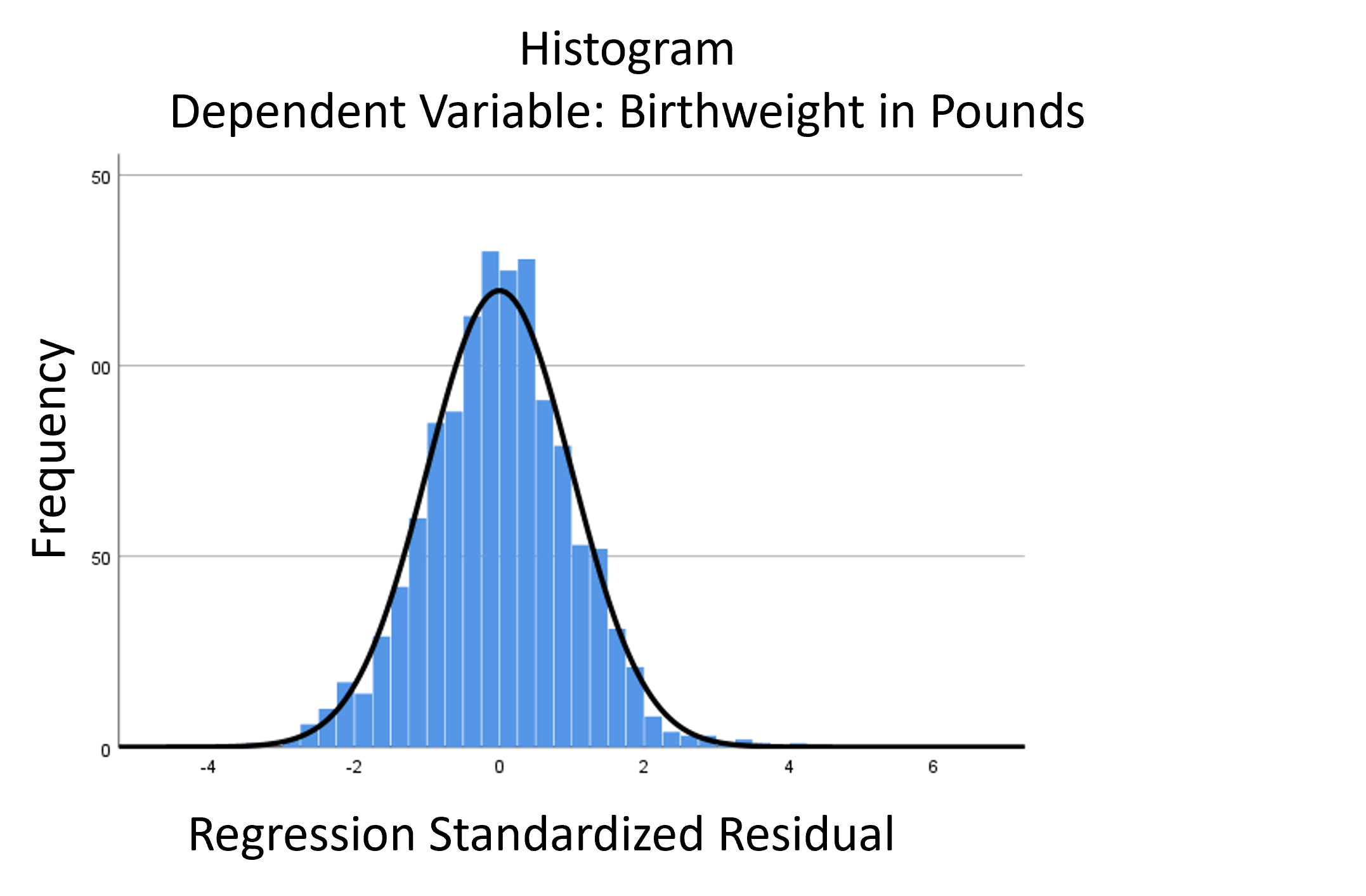 assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.