The linear model normality assumption, along with constant variance assumption, is quite robust to departures. That means that even if the 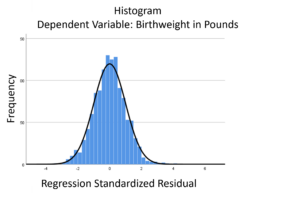 assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
This is great because it gives you a bit of leeway to run linear models, which are intuitive and (relatively) straightforward. This is true for both linear regression and ANOVA.
You do need to check the assumptions anyway, though. You can’t just claim robustness and not check. Why? Because some departures are so far off that the p-values and confidence intervals become inaccurate. And in many cases there are remedial measures you can take to turn non-normal residuals into normal ones.
But sometimes you can’t.
Sometimes it’s because the dependent variable just isn’t appropriate for a linear model. The (more…)
There are not a lot of statistical methods designed just to analyze ordinal variables.
But that doesn’t mean that you’re stuck with few options. There are more than you’d think.
Some are better than others, but it depends on the situation and research questions.
Here are five options when your dependent variable is ordinal.
(more…)
 Multinomial logistic regression is an important type of categorical data analysis. Specifically, it’s used when your response variable is nominal: more than two categories and not ordered.
Multinomial logistic regression is an important type of categorical data analysis. Specifically, it’s used when your response variable is nominal: more than two categories and not ordered.
(more…)
When your dependent variable is not continuous, unbounded, and measured on an interval or ratio scale, linear models don’t fit. The data just will not meet the assumptions of linear models. But there’s good news, other models exist for many types of dependent variables.
Today I’m going to go into more detail about 6 common types of dependent variables that are either discrete, bounded, or measured on a nominal or ordinal scale and the tests that work for them instead. Some are all of these.
(more…)
Interpreting the results of logistic regression can be tricky, even for people who are familiar with performing different kinds of statistical analyses. How do we then share these results with non-researchers in a way that makes sense?
(more…)

In the world of statistical analyses, there are many tests and methods that for categorical data. Many become extremely complex, especially as the number of variables increases. But sometimes we need an analysis for only one or two categorical variables at a time. When that is the case, one of these seven fundamental tests may come in handy.
These tests apply to nominal data (categories with no order to them) and a few can apply to other types of data as well. They allow us to test for goodness of fit, independence, or homogeneity—and yes, we will discuss the difference! Whether these tests are new to you, or you need a good refresher, this training will help you understand how they work and when each is appropriate to use.
(more…)
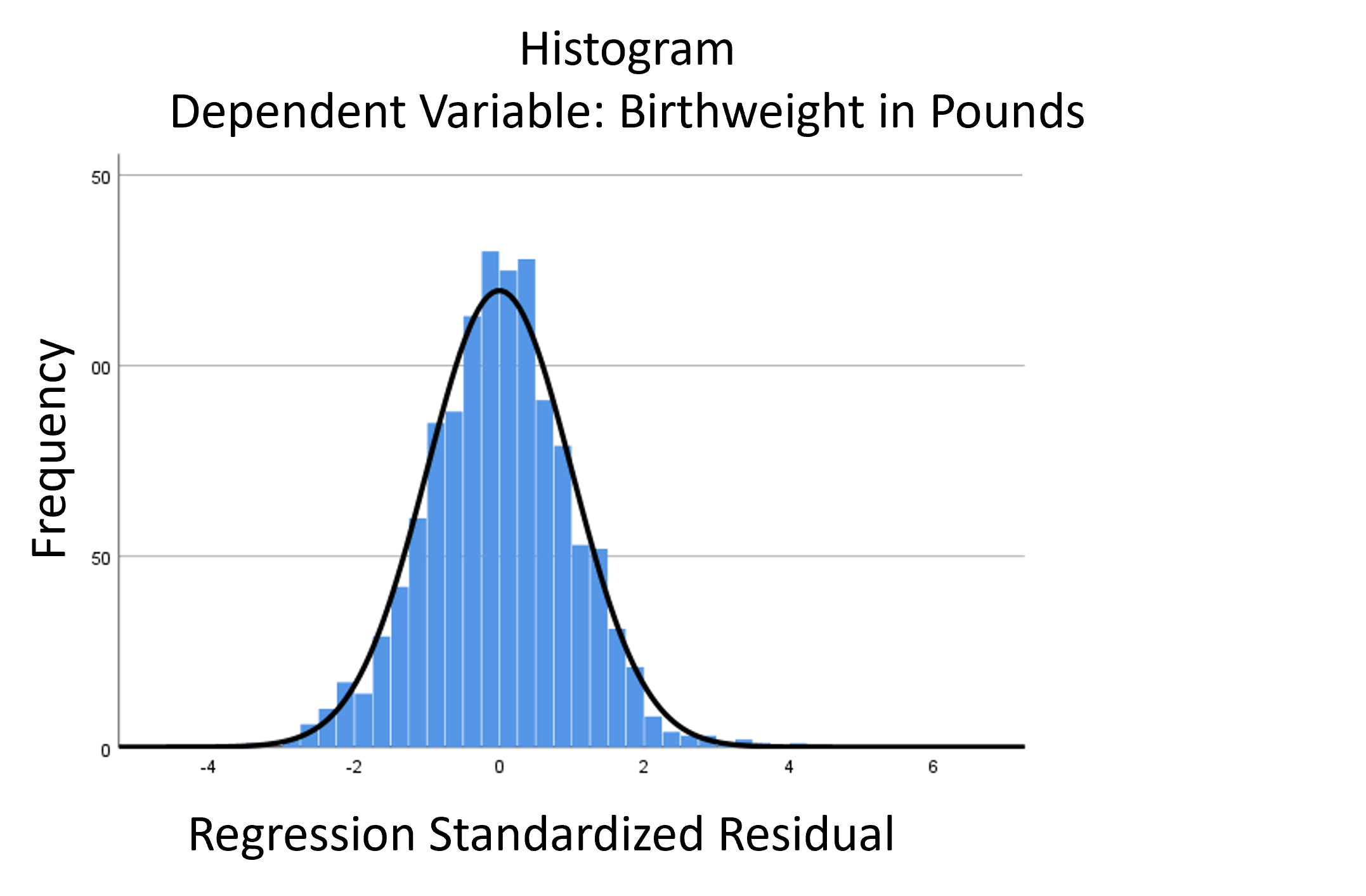 assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.