Stata makes it a breeze to edit or clean your data. If you’re unfamiliar with using data sets in Stata, check out these blog posts to get a good grasp on importing and browsing data in Stata.
For this tutorial we will be using Stata’s “auto” data set. If you haven’t loaded it in yet, type
sysuse auto, clear
Stata’s Data Editor
One way to change data in Stata is to use the data editor. This can be reached by clicking the Data Editor (Edit) button at the top of the screen

Or by typing the command
edit
into the command line
You should now be viewing this display
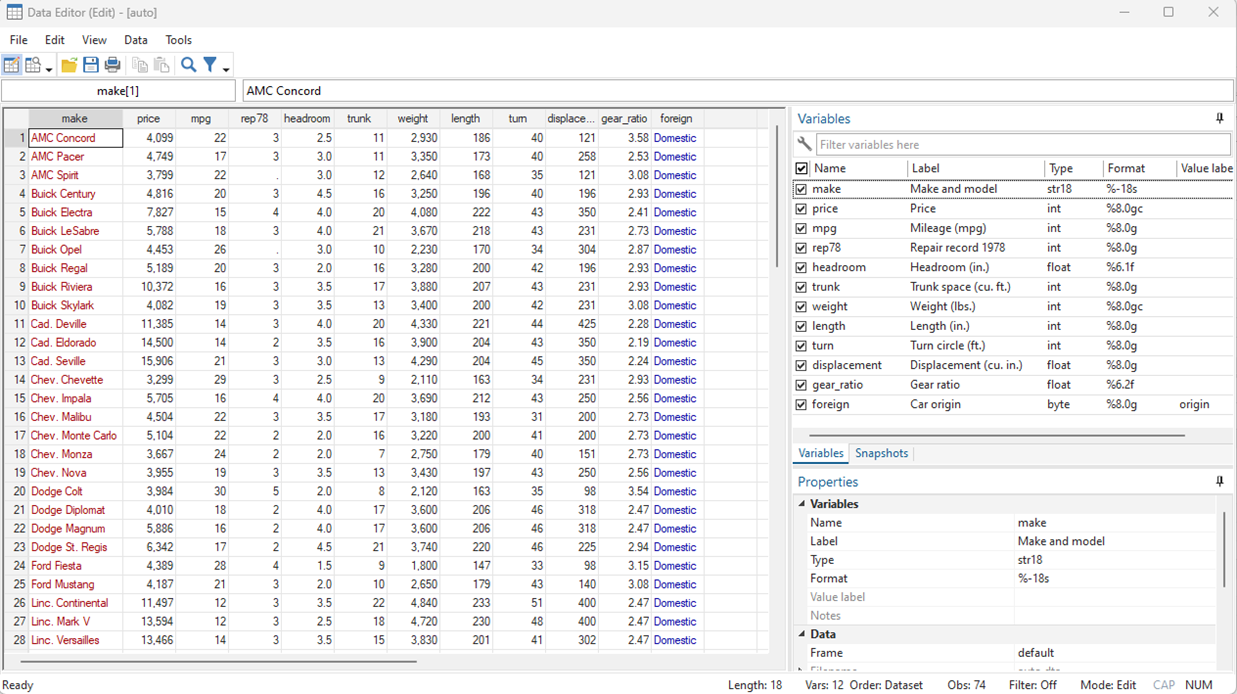
If you’ve already explored the Data Editor (Browse), you’ll notice this looks quite similar.
The difference is that it is now possible to change the data directly from this spreadsheet, the same as if it were an Excel file.
To demonstrate this, click on the second observation in the “trunk” column. Delete this observation and replace it with a period (missing value), then press enter.
After entering this, you should see the following code in the results window:
replace trunk = . in 2
Try to change it back to 11 using syntax
replace trunk = 11 in 2
Editing Data with Stata Syntax
While editing data with the Stata browser will work, it is not recommended, especially for more complicated edits.
It is better to learn how to edit your data using syntax so that all data cleaning can be put in a do-file.
Cleaning data without a do-file might lead you to lose track of which edits you made. And that’s a real problem for reproducibility and defending your analysis.
For the rest of this series, we’ll focus on using syntax to make our edits. In this article, we’ll go over using some of Stata’s simplest editing commands: those to save data sets, reorder variables, and drop variables.
save (saves dataset to your device)
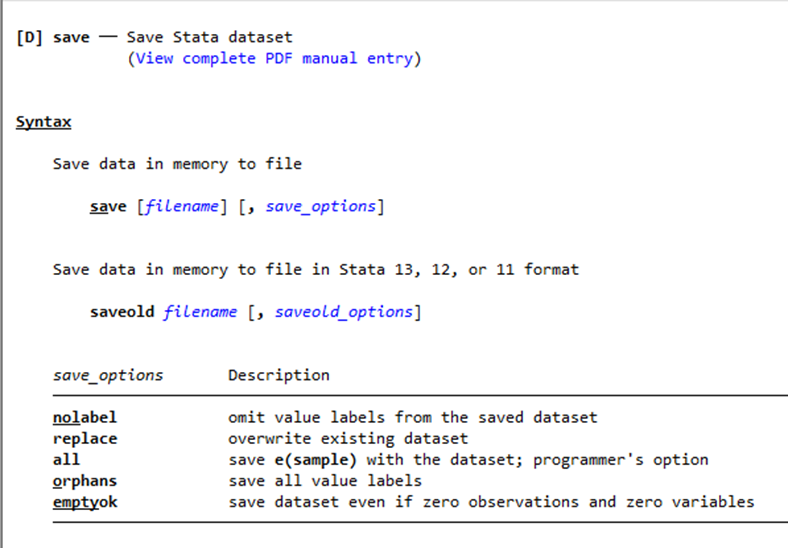
Before making edits to a data set, the first thing you should plan to do is save a copy.
Even if using a do-file, it is possible to make changes to a data set that you don’t know how to switch back.
To prevent this issue, save the data set right when you start.
The save command is also helpful after doing the cleaning; you may want to save the altered version of your dataset.
Before using the save command, set your directory to the place where you want the file saved. This is done by entering the command “cd”, followed by the directory you want to save the dataset to.
So I will enter
cd “C:\Users\james\OneDrive\Documents\Analysis Factor\Stata blog post datasets”
then
save auto
And the data set is now saved as a .dta file in the chosen folder
If you made changes and then try to save the auto data again, it will tell you that you’re overwriting the data in the directory.
You can override this warning with the replace option.
(save auto, replace)
If I wanted to save an altered version of the data set with a different name, I could enter the save command and the full file path with a different name (“cars”), like so:
save “C:\Users\james\OneDrive\Documents\Analysis Factor\Stata blog post datasets\cars.dta”
I highly recommend you do this at the very beginning to create a backup data set you can always go back to.
Drop and keep (removes observations or variables)

The drop command removes the selected variables or observations from the data set.
To remove the make and price variables, type
drop make price
And see how these two variables completely leave the dataset.
To remove all foreign cars from the dataset, type
drop if foreign == 1
Note that when drop removes observations, it doesn’t fill them in with missing data. It completely cleanses the observations from the data.
If we wanted to fill in certain observations with missing data, we would need to use replace or recode.
Keep has the same capabilities as drop, but works in an opposite way. Any variables or observations that we don’t select get removed. Type the following two lines
keep mpg rep78 foreign
keep if mpg<21
Now we removed all variables except for mpg, rep78, and foreign. We removed all observations except the ones where mpg is less than 21.
order (changes order of variables)
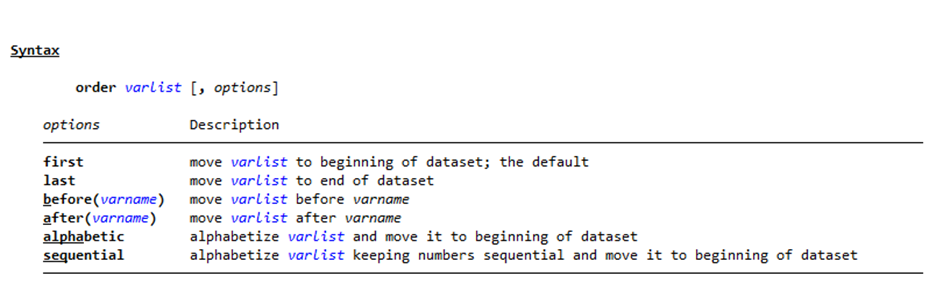
Order is a simple command used to change the order of variables in a dataset.
Let’s get a new version of the auto dataset now that we made so many changes.
sysuse auto, clear
Imagine we wanted this dataset reorganized so that foreign moves to the second position. We could type any of the following:
order make foreign (moves make and foreign to the beginning)
order foreign, b(price) (moves foreign to be before price)
order foreign, a(make) (moves foreign to be after make)
order make foreign price mpg rep78 headroom trunk weight length turn displacement gear_ratio (Directly places every variable in the order I want)
Order can also be used to alphabetize some or all of the variable list.
More Cleaning to be Done
You should feel comfortable with the basic structure of editing Stata datasets, but you still may lack a lot of the tools you need. Join us in the next article where we talk about using replace, generate, egen, and clonevar to create new variables in a dataset.
by James Harrod
About the Author: James Harrod interned at The Analysis Factor in the summer of 2023. He plans to continue into a career as an actuary, and hopes to continue finding interesting ways of educating people about statistics. James is well-versed in R and Stata programming and enjoys teaching the intuition behind common statistical methods. James is a 2023 graduate of the University of Rochester with bachelor’s degrees in Statistics and Economics.

Leave a Reply