In a previous post we discussed using marginal means to explain an interaction to a non-statistical audience. The output from a linear regression model can be a bit confusing. This is the model that was shown.
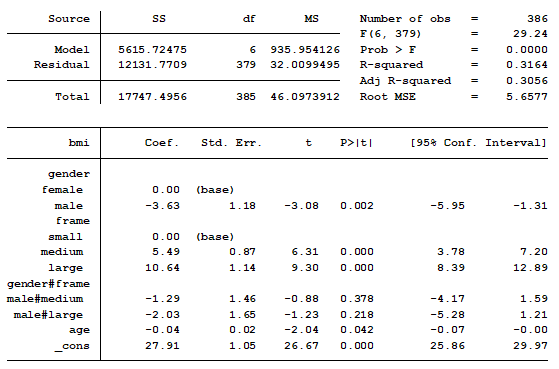
In this model, BMI is the outcome variable and there are three predictors:
(more…)
 When you put a continuous predictor into a linear regression model, you assume it has a constant relationship with the dependent variable along the predictor’s range. But how can you be certain? What is the best way to measure this?
When you put a continuous predictor into a linear regression model, you assume it has a constant relationship with the dependent variable along the predictor’s range. But how can you be certain? What is the best way to measure this?
And most important, what should you do if it clearly isn’t the case?
Let’s explore a few options for capturing a non-linear relationship between X and Y within a linear regression (yes, really). (more…)
Sometimes what is most tricky about understanding your regression output is knowing exactly what your software is presenting to you.
Here’s a great example of what looks like two completely different model results from SPSS and Stata that in reality, agree.
The Model
I ran a linear model regressing “physical composite score” on education and “mental composite score”.
The outcome variable, physical composite score, is a measurement of one’s physical well-being. The predictor “education” is categorical with four categories. The other predictor, mental composite score, is continuous and measures one’s mental well-being.
I am interested in determining whether the association between physical composite score and mental composite score is different among the four levels of education. To determine this I included an interaction between mental composite score and education.
The SPSS Regression Output
Here is the result of the regression using SPSS:
(more…)
In your typical statistical work, chances are you have already used quantiles such as the median, 25th or 75th percentiles as descriptive statistics.
But did you know quantiles are also valuable in regression, where they can answer a broader set of research questions than standard linear regression?
In standard linear regression, the focus is on estimating the mean of a response variable given a set of predictor variables.
In quantile regression, we can go beyond the mean of the response variable. Instead we can understand how predictor variables predict (1) the entire distribution of the response variable or (2) one or more relevant features (e.g., center, spread, shape) of this distribution.
For example, quantile regression can help us understand not only how age predicts the mean or median income, but also how age predicts the 75th or 25th percentile of the income distribution.
Or we can see how the inter-quartile range — the width between the 75th and 25th percentile — is affected by age. Perhaps the range becomes wider as age increases, signaling that an increase in age is associated with an increase in income variability.
In this webinar, we will help you become familiar with the power and versatility of quantile regression by discussing topics such as:
- Quantiles – a brief review of their computation, interpretation and uses;
- Distinction between conditional and unconditional quantiles;
- Formulation and estimation of conditional quantile regression models;
- Interpretation of results produced by conditional quantile regression models;
- Graphical displays for visualizing the results of conditional quantile regression models;
- Inference and prediction for conditional quantile regression models;
- Software options for fitting quantile regression models.
Join us on this webinar to understand how quantile regression can be used to expand the scope of research questions you can address with your data.
Note: This training is an exclusive benefit to members of the Statistically Speaking Membership Program and part of the Stat’s Amore Trainings Series. Each Stat’s Amore Training is approximately 90 minutes long.
(more…)
Many who work with statistics are already functionally familiar with the normal distribution, and maybe even the binomial distribution.
These common distributions are helpful in many applications, but what happens when they just don’t work?
This webinar will cover a number of statistical distributions, including the:
- Poisson and negative binomial distributions (especially useful for count data)
- Multinomial distribution (for responses with more than two categories)
- Beta distribution (for continuous percentages)
- Gamma distribution (for right-skewed continuous data)
- Bernoulli and binomial distributions (for probabilities and proportions)
- And more!
We’ll also explore the relationships among statistical distributions, including those you may already use, like the normal, t, chi-squared, and F distributions.
Note: This training is an exclusive benefit to members of the Statistically Speaking Membership Program and part of the Stat’s Amore Trainings Series. Each Stat’s Amore Training is approximately 90 minutes long.
(more…)
Pretty much all of the common statistical models we use, with the exception of OLS Linear Models, use Maximum Likelihood estimation.
This includes favorites like:
That’s a lot of models.
If you’ve ever learned any of these, you’ve heard that some of the statistics that compare model fit in competing models require (more…)