
Multicollinearity is one of those terms in statistics that is often defined in one of two ways:
1. Very mathematical terms that make no sense — I mean, what is a linear combination anyway?
2. Completely oversimplified in order to avoid the mathematical terms — it’s a high correlation, right?
So what is it really? In English?
(more…)
How do you know your variables are measuring what you think they are? And how do you know they’re doing it well?
A key part of answering these questions is establishing reliability and validity of the measurements that you use in your research study. But the process of establishing reliability and validity is confusing. There are a dizzying number of choices available to you.
(more…)
The following statement might surprise you, but it’s true.
To run a linear model, you don’t need an outcome variable Y that’s normally distributed. Instead, you need a dependent variable that is:
- Continuous
- Unbounded
- Measured on an interval or ratio scale
The normality assumption is about the errors in the model, which have the same distribution as Y|X. It’s absolutely possible to have a skewed distribution of Y and a normal distribution of errors because of the effect of X. (more…)
What is a Confounder?
Confounder (also called confounding variable) is one of those statistical terms that confuses a lot of people. Not because it represents a confusing concept, but because of how it’s used.
(Well, it’s a bit of a confusing concept, but that’s not the worst part).
It has slightly different meanings to different types of researchers. The definition is essentially the same, but the research context can have specific implications for how that definition plays out.
If the person you’re talking to has a different understanding of what it means, you’re going to have a confusing conversation.
Let’s take a look at some examples to unpack this.
(more…)
At times it is necessary to convert a continuous predictor into a categorical predictor. For example, income per household is shown below.
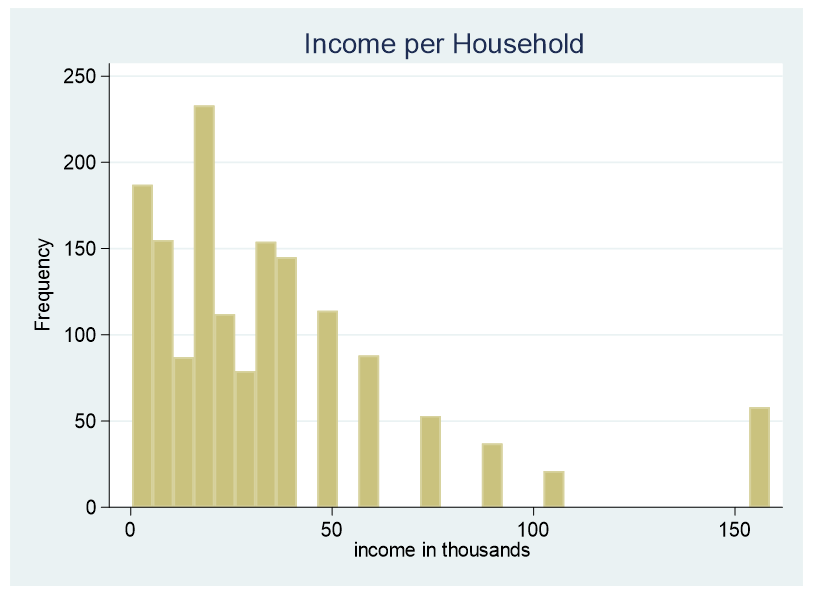
This data is censored, all family income above $155,000 is stated as $155,000. A further explanation about censored and truncated data can be found here. It would be incorrect to use this variable as a continuous predictor due to its censoring.
(more…)
In a recent article, we reviewed the impact of removing the intercept from a regression model when the predictor variable is categorical. This month we’re going to talk about removing the intercept when the predictor variable is continuous.
Spoiler alert: You should never remove the intercept when a predictor variable is continuous.
Here’s why. (more…)