From our last posts in this series, you should be comfortable with how Stata handles data editing, as well as with making your own variables. In this post, we’ll talk about commands that edit the content or storage type of your variables in Stata: recode and recast. Let’s start off with the recode command.
OptinMon
Getting Started with Stata Tutorial #11: Editing Variables Using recode and recast
May 12th, 2025 by TAF Support
Getting Started with Stata Tutorial #10: Four Commands to Create New Variables in Stata
April 29th, 2025 by TAF Support
From our last article, you should feel comfortable with the idea of editing and saving data sets in Stata. In this article, we’ll explain how to create new variables in Stata using replace, generate, egen, and clonevar.
Strategies for Choosing and Planning a Statistical Analysis
April 22nd, 2025 by Karen Grace-Martin
The first real data set I ever analyzed was from my senior honors thesis as an undergraduate psychology major. I had taken both intro stats and an ANOVA class, and I applied all my new skills with gusto, analyzing every which way.
It wasn’t too many years into graduate school that I realized that these data analyses were a bit haphazard. (Okay, a LOT). And honestly, not at all well thought out.
A few decades of data analysis experience later, I realized that’s just a symptom of being an inexperienced data analyst.
But even experienced data analysts can get off track. It’s especially easy with large data sets with many variables. It’s just so tempting to try one thing, then another, and pretty soon you’ve spent weeks getting nowhere.
Getting Started with Stata Tutorial #9: Saving, Reordering, and Dropping Data
March 17th, 2025 by TAF Support
Stata makes it a breeze to edit or clean your data. If you’re unfamiliar with using data sets in Stata, check out these blog posts to get a good grasp on importing and browsing data in Stata.
For this tutorial we will be using Stata’s “auto” data set. If you haven’t loaded it in yet, type
6 Types of Dependent Variables that will Never Meet the Linear Model Normality Assumption
February 18th, 2025 by Karen Grace-Martin
The linear model normality assumption, along with constant variance assumption, is quite robust to departures. That means that even if the 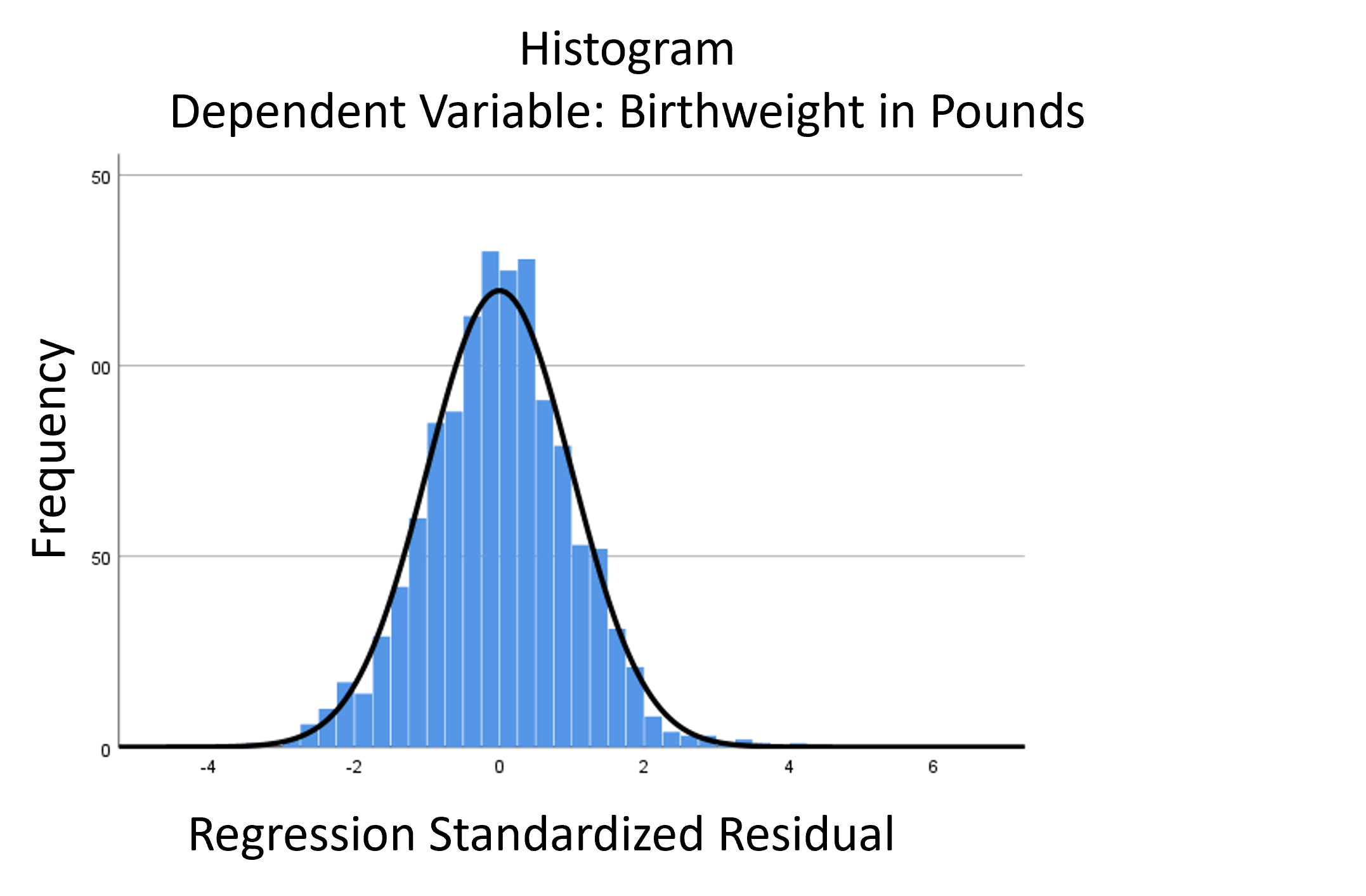 assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
assumptions aren’t met perfectly, the resulting p-values and confidence intervals will still be reasonable estimates.
This is great because it gives you a bit of leeway to run linear models, which are intuitive and (relatively) straightforward. This is true for both linear regression and ANOVA.
You do need to check the assumptions anyway, though. You can’t just claim robustness and not check. Why? Because some departures are so far off that the p-values and confidence intervals become inaccurate. And in many cases there are remedial measures you can take to turn non-normal residuals into normal ones.
But sometimes you can’t.
Sometimes it’s because the dependent variable just isn’t appropriate for a linear model. The (more…)
The Best Reasons to Run a Pilot Study
February 11th, 2025 by guest contributer
 There’s a common saying among pediatricians: children are not little adults. You can’t take a drug therapy that works in adults and scale it down to a kid-sized treatment.
There’s a common saying among pediatricians: children are not little adults. You can’t take a drug therapy that works in adults and scale it down to a kid-sized treatment.
Children are actively growing. Their livers metabolize drugs differently, and they have a stage of life called puberty that many of us have long forgotten.
Likewise, pilot studies are not little research studies. Please do not take a poorly funded clinical trial and try to sneak your inadequate sample size through peer review by calling it a pilot.