At The Analysis Factor, we are on a mission to help researchers improve their statistical skills so they can do amazing research.
We all tend to think of “Statistical Analysis” as one big skill, but it’s not.
Over the years of training, coaching, and mentoring data analysts at all stages, I’ve realized there are four fundamental stages of statistical skill:
 Stage 1:
Stage 1: The Fundamentals

Stage 2: Linear Models

Stage 3: Extensions of Linear Models

Stage 4: Advanced Models
There is also a stage beyond these where the mathematical statisticians dwell. But that stage is required for such a tiny fraction of data analysis projects, we’re going to ignore that one for now.
If you try to master the skill of “statistical analysis” as a whole, it’s going to be overwhelming.
And honestly, you’ll never finish. It’s too big of a field.
But if you can work through these stages, you’ll find you can learn and do just about any statistical analysis you need to. (more…)
 When you put a continuous predictor into a linear regression model, you assume it has a constant relationship with the dependent variable along the predictor’s range. But how can you be certain? What is the best way to measure this?
When you put a continuous predictor into a linear regression model, you assume it has a constant relationship with the dependent variable along the predictor’s range. But how can you be certain? What is the best way to measure this?
And most important, what should you do if it clearly isn’t the case?
Let’s explore a few options for capturing a non-linear relationship between X and Y within a linear regression (yes, really). (more…)
We’ve talked a lot around here about the reasons to use syntax — not only menus — in your statistical analyses.
Regardless of which software you use, the syntax file is pretty much always a text file. This is true for R, SPSS, SAS, Stata — just about all of them.
This is important because it means you can use an unlikely tool to help you code: Microsoft Word.
I know what you’re thinking. Word? Really?
Yep, it’s true. Essentially it’s because Word has much better Search-and-Replace options than your stat software’s editor.
Here are a couple features of Word’s search-and-replace that I use to help me code faster:
(more…)
There are many rules of thumb in statistical analysis that make decision making and understanding results much easier.
Have you ever stopped to wonder where these rules came from, let alone if there is any scientific basis for them? Is there logic behind these rules, or is it propagation of urban legends?
In this webinar, we’ll explore and question the origins, justifications, and some of the most common rules of thumb in statistical analysis, like:
(more…)
Not too long ago, a colleague mentioned that while he does a lot of study design these days, he no longer does much data analysis.
His main reason was that 80% of the work in data analysis is preparing the data for analysis. Data preparation is s-l-o-w and he found that few colleagues and clients understood this.
Consequently, he was running into expectations that he should analyze a raw data set in an hour or so.
You know, by clicking a few buttons.
I see this as well with researchers new to data analysis. While they know it will take longer than an hour, they still have unrealistic expectations about how long it takes.
So I am here to tell you, the time-consuming part is preparing the data. Weeks is a realistic time frame. Hours is not.
(Feel free to send this to your colleagues who want instant results.)
There are three parts to preparing data: cleaning it, creating necessary variables, and formatting all variables.
Data Cleaning
Data cleaning means finding and eliminating errors in the data. How you approach it depends on how large the data set is, but the kinds of things you’re looking for are: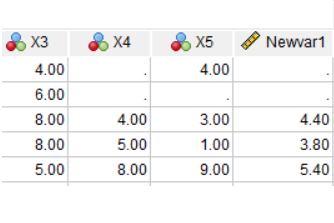
- Impossible or otherwise incorrect values for specific variables
- Cases in the data who met exclusion criteria and shouldn’t be in the study
- Duplicate cases
- Missing data and outliers (don’t delete all outliers, but you may need to investigate to see if one is an error)
- Skip-pattern or logic breakdowns
- Making sure that the same value of string variables is always written the same way (male ≠ Male in most statistical software).
You can’t avoid data cleaning and it always takes a while, but there are ways to make it more efficient. For example, rather than search through the data set for impossible values, print a table of data values outside a normal range, along with subject ids.
This is where learning how to code in your statistical software of choice really helps. You’ll need to subset your data using IF statements to find those impossible values.
But if your data set is anything but small, you can also save yourself a lot of time, code, and errors by incorporating efficiencies like loops and macros so that you can perform some of these checks on many variables at once.
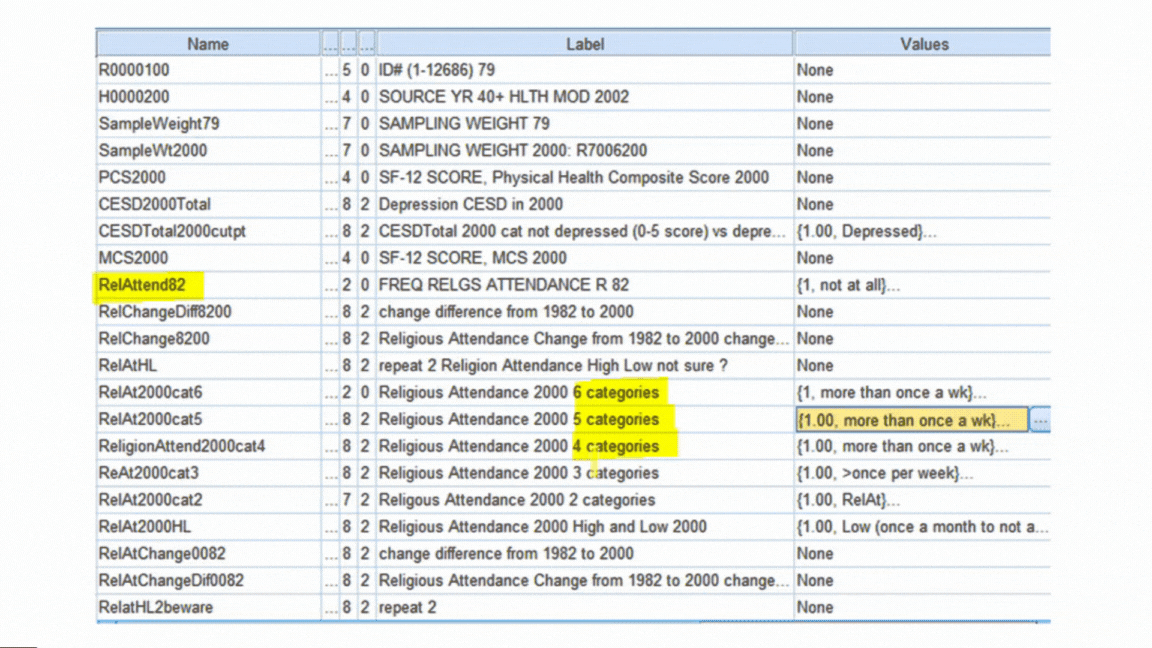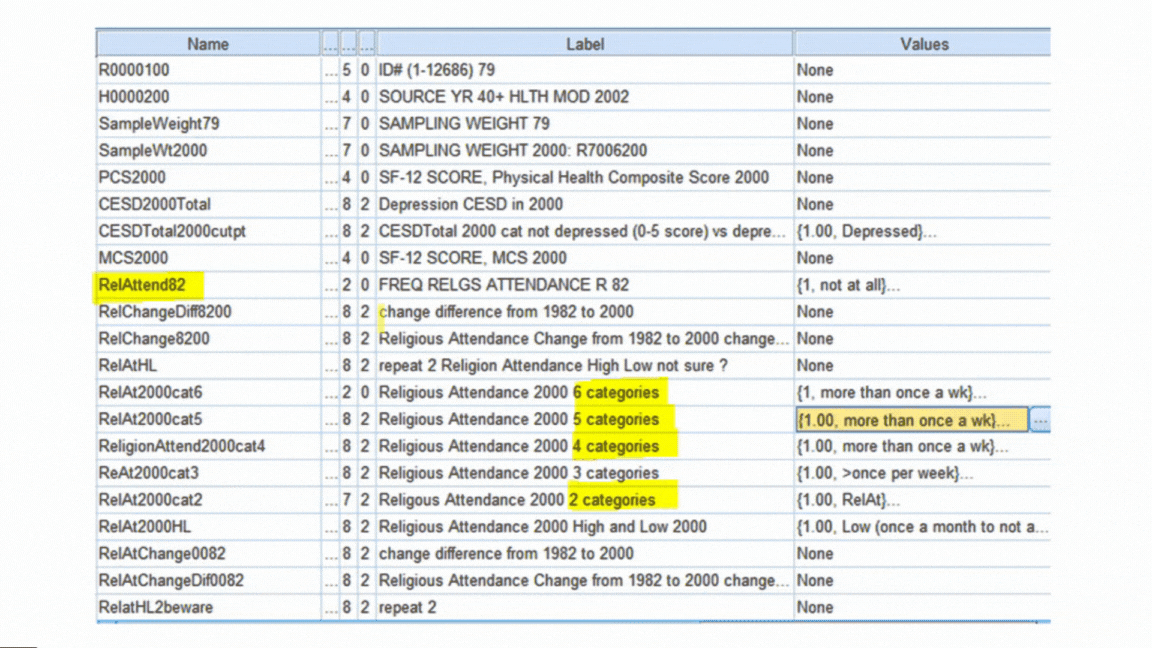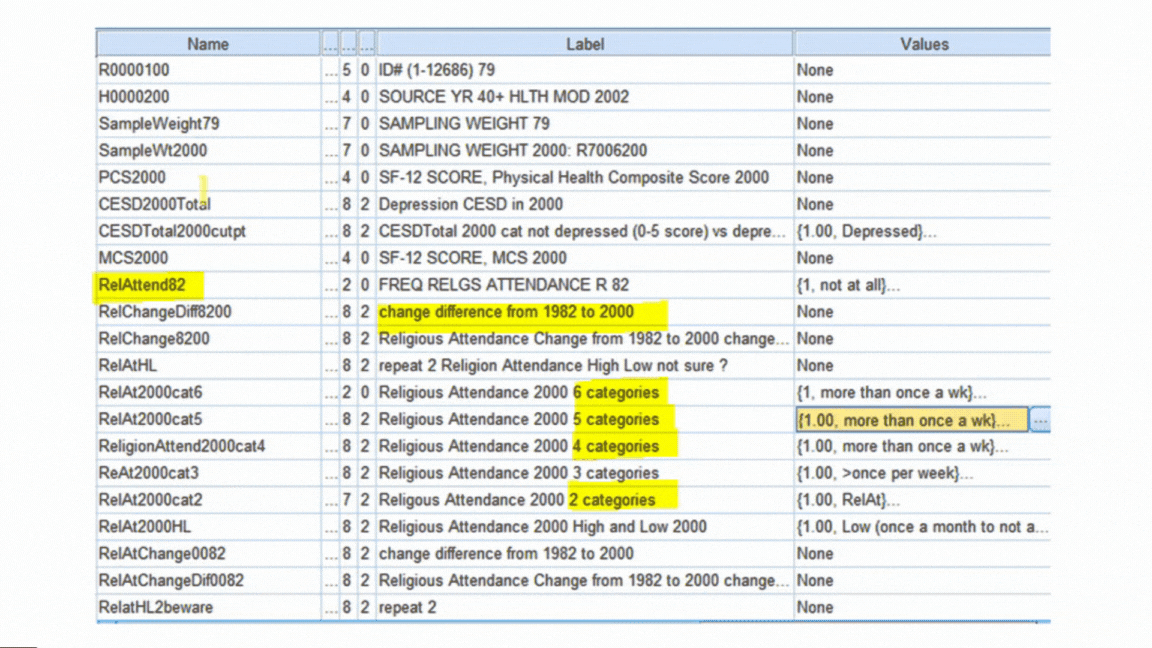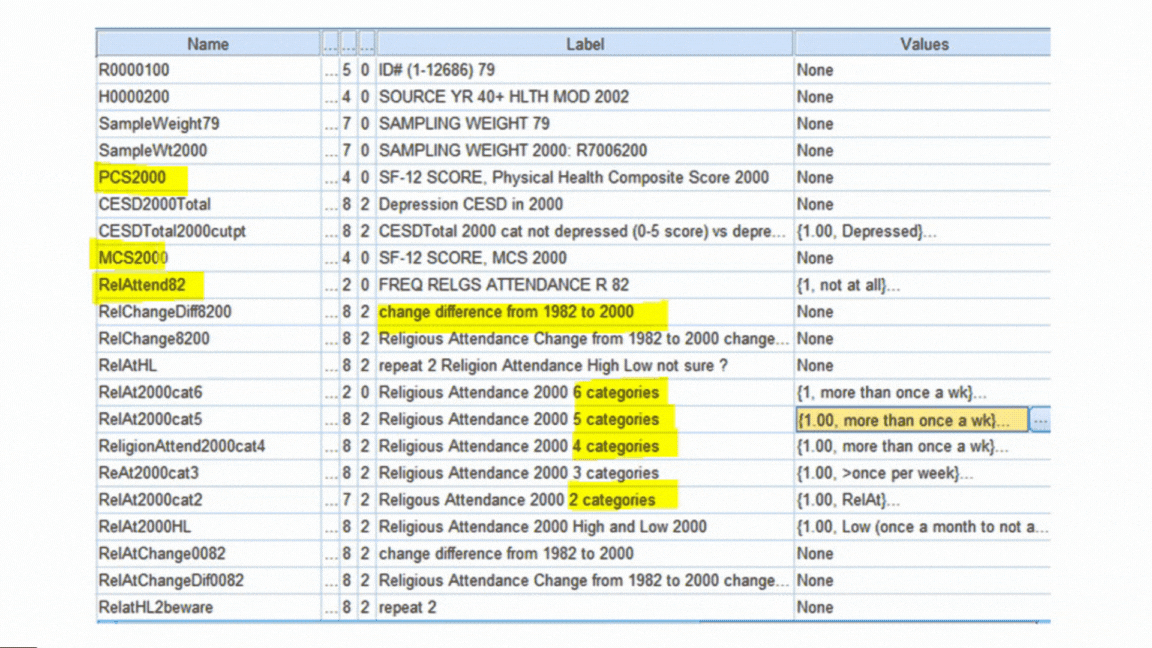
Creating New Variables
Once the data are free of errors, you need to set up the variables that will directly answer your research questions.
It’s a rare data set in which every variable you need is measured directly.
So you may need to do a lot of recoding and computing of variables.
Examples include:
And of course, part of creating each new variable is double-checking that it worked correctly.
Formatting Variables
Both original and newly created variables need to be formatted correctly for two reasons:
First, so your software works with them correctly. Failing to format a missing value code or a dummy variable correctly will have major consequences for your data analysis.
Second, it’s much faster to run the analyses and interpret results if you don’t have to keep looking up which variable Q156 is.
Examples include:
- Setting all missing data codes so missing data are treated as such
- Formatting date variables as dates, numerical variables as numbers, etc.
- Labeling all variables and categorical values so you don’t have to keep looking them up.
All of these steps require a solid knowledge of how to manage data in your statistical software. Each one approaches them a little differently.
It’s also very important to keep track of and be able to easily redo all your steps. Always assume you’ll have to redo something. So use (or record) syntax, not only menus.
Do I really need to learn R?
Someone asked me this recently.
Many R advocates would absolutely say yes to everyone who asks.
I don’t.
(I actually gave her a pretty long answer, summarized here).
It depends on what kind of work you do and the context in which you’re working.
I can say that R is (more…)