 If you’ve used much analysis of variance (ANOVA), you’ve probably heard that ANOVA is a special case of linear regression. Unless you’ve seen why, though, that may not make a lot of sense. After all, ANOVA compares means between categories, while regression predicts outcomes with numeric variables.
If you’ve used much analysis of variance (ANOVA), you’ve probably heard that ANOVA is a special case of linear regression. Unless you’ve seen why, though, that may not make a lot of sense. After all, ANOVA compares means between categories, while regression predicts outcomes with numeric variables. (more…)
(more…)
ANOVA
Member Training: The Link Between ANOVA and Regression
January 31st, 2023 by TAF Support
Can Likert Scale Data ever be Continuous?
January 19th, 2023 by Karen Grace-Martin
A very common question is whether it is legitimate to use Likert scale data in parametric statistical procedures that  require interval data, such as Linear Regression, ANOVA, and Factor Analysis.
require interval data, such as Linear Regression, ANOVA, and Factor Analysis.
A typical Likert scale item has 5 to 11 points that indicate the degree of something. For example, it could measure agreement with a statement, such as 1=Strongly Disagree to 5=Strongly Agree. It can be a 1 to 5 scale, 0 to 10, etc. (more…)
What is a Dunnett’s Test?
January 10th, 2023 by guest contributer
I’m a big fan of Analysis of Variance (ANOVA). I use it all the time. I learn a lot from it. But sometimes it doesn’t test the hypothesis I need. In this article, we’ll explore a test that is used when you care about a specific comparison among means: Dunnett’s test. (more…)
(more…)
When the Results of Your ANOVA Table and Regression Coefficients Disagree
December 8th, 2022 by Karen Grace-Martin
Have you ever had this happen? You run a regression model. It can be any kind—linear, logistic, multilevel, etc. In the ANOVA table, the effect of interest has a very low p-value. In the regression table, it doesn’t. Or vice-versa.
How can the same effect have two different p-values? In this article, let’s explore when this happens and what it means.
What the statistics in each table measures
The ANOVA table is a table of F tests. It may not be called the ANOVA table on your output, but it always includes a set of F tests. Some software procedures only give one F test for the model as a whole, but most will break it down into a series of F tests, one for each predictor variable or term in your model.
The regression coefficients table is a table of t tests. It includes each regression coefficient, along with its standard error, and usually a t test (some generalized linear models will have Wald or z tests instead, but they have the same role here).
Both tables often list out each predictor variable, along with a p-value for that variable’s conditional effect on Y.
There are two situations in which the p-values will match. Both must be true.
- The F test has one df. This happens in two situations. Either the predictor, X, is numerical or it’s categorical and binary (only two groups).
- The predictor is not involved with any interactions with a variable that is not centered at is mean.
If both of those are true, not only will the p-value match, but the t-statistic in the regression coefficients table will be the positive or negative square root of the F statistic.
An Example ANOVA Table with Matching and Unmatching Regression Coefficients
Here’s an example of an ANOVA table from a linear regression. In this example, there are four treatment groups, two genders, and age in years (measured continuously and centered at its mean). The response variable, Y, is a satisfaction score with a training. The four groups represented four learning strategies the adult learners were trained to use.
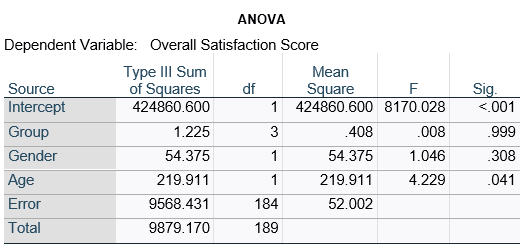
Let’s compare this to the regression coefficients table.
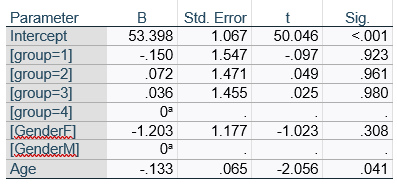
If you compare p-values across the two tables, you can see that Gender and Age have the same p-values, but Group doesn’t.
Gender and Age meet both conditions. Both have 1 df in the F table. Gender because it’s binary (two categories) and Age because it’s numerical). There are no interactions.
Group doesn’t match because it has 3 df in the F test. The F test is testing the null hypothesis that there is no difference among the four means. The t-tests in the regression coefficients table are testing three specific contrasts. Each one compares one group mean to the group 4 mean. For example, the group=1 coefficient tests whether the difference between the mean group 1 satisfaction score differs only from the group 4 score. It’s a different null hypothesis than the F test.
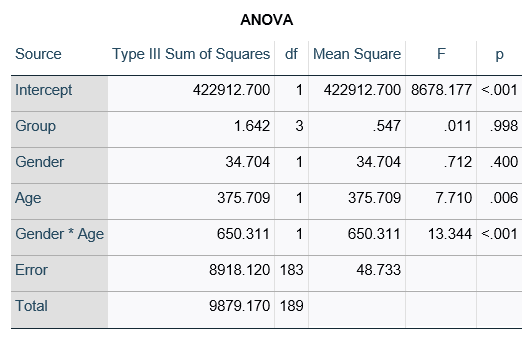
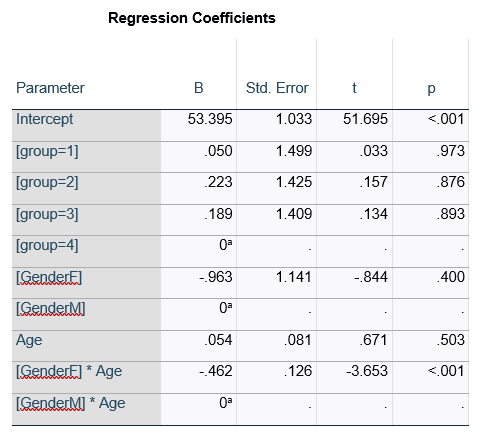
This would be the case whether or not there were interactions in the model that contain Group. Any time you have more that one df in the F test (you can see group has 3), you’ll get as many p-values in the regression coefficients as you have df in the F table. The p-values can’t match because there are more of them in the regression coefficients table.
Gender, which is also categorical, does have the same p-value in both tables. It has 1 df in the F test, which tests the null hypothesis that the two gender means have no variance (they’re the same). Gender is involved in an interaction, so the only reason the hypothesis test, and therefore the p-value, is the same is because the variable it interacts with, Age, is centered.
In conclusion, most of the time, it’s fine if the results don’t match. It’s because the two tables are reporting results of different hypothesis tests, based on what’s in your model.
Member Training: Centering
November 30th, 2022 by TAF Support
Centering variables is common practice in some areas, and rarely seen in others. That being the case, it isn’t always clear what are the reasons for centering variables.  Is it only a matter of preference, or does centering variables help with analysis and interpretation? (more…)
Is it only a matter of preference, or does centering variables help with analysis and interpretation? (more…)
An Example of Specifying Within-Subjects Factors in Repeated Measures
September 19th, 2022 by Karen Grace-Martin
Some repeated measures designs make it quite challenging to specify within-subjects factors. Especially difficult is when the design contains two “levels” of repeat, but your interest is in testing just one.
Let’s look at a great example of what this looks like and how to deal with it in this question from a reader :
The Design:
I want to do a GLM (repeated measures ANOVA) with the valence of some actions of my test-subjects (valence = desirability of actions) as a within-subject factor. My subjects have to rate a number of actions/behaviours in a pre-set list of 20 actions from ‘very likely to do’ to ‘will never do this’ on a scale from 1 to 7, and some of these actions are desirable (e.g. help a blind man crossing the street) and therefore have a positive valence (in psychology) and some others are non-desirable (e.g. play loud music at night) and therefore have negative valence in psychology.
My question is how I can use valence as a within-subjects factor in GLM. Is there a way to tell SPSS some actions have positive valence and others have negative valence ? I assume assigning labels to the actions will not do it, as SPSS does not make analyses based on labels …
Please help. Thank you.