Previous Posts
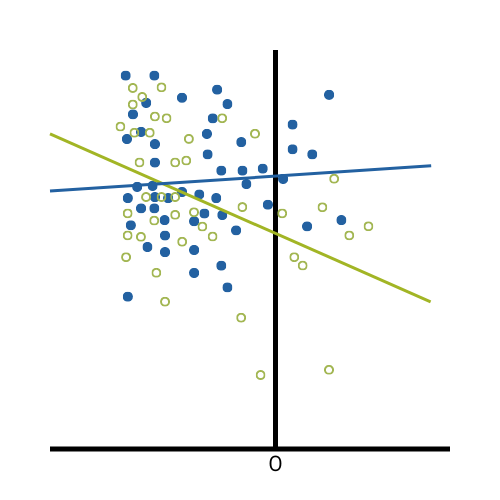
Centering variables is common practice in some areas, and rarely seen in others. That being the case, it isn’t always clear what are the reasons for centering variables. Is it only a matter of preference, or does centering variables help with analysis and interpretation?
One of the important issues with missing data is the missing data mechanism. It's important because it affects how much the missing data bias your results, so you have to take it into account when choosing an approach to deal with the missing data. The concepts of these mechanisms can be a bit abstract. And to top it off, two of these mechanisms have confusing names: Missing Completely at Random and Missing at Random.
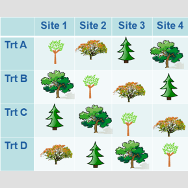
The most basic experimental design is the completely randomized design. It is simple and straightforward when plenty of unrelated subjects are available for an experiment. It’s so simple, it almost seems obvious. But there are important principles in this simple design that are important for tackling more complex experimental designs. Let’s take a look. How […]
Data analysts can get away without ever understanding matrix algebra, certainly. But there are times when having even a basic understanding of how matrix algebra works and what it has to do with data can really make your analyses make a little more sense.
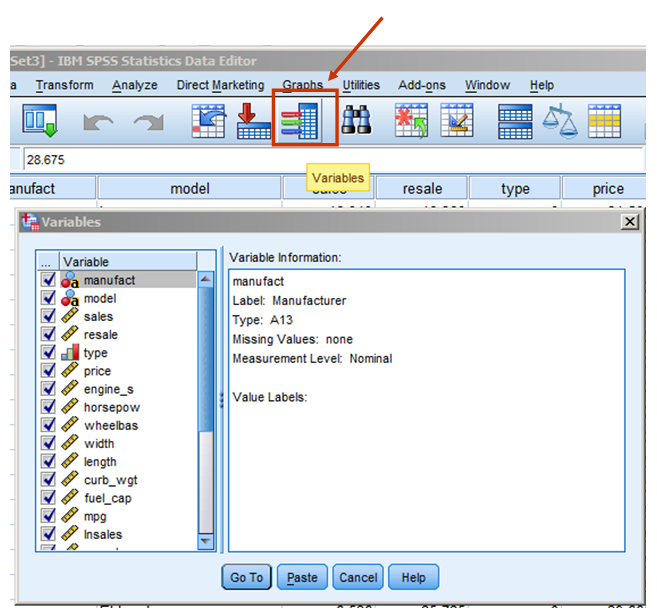
When I consult with researchers, a common part of that is going through their analysis together. Sometimes I notice that they're using some shortcut in SPSS that I had not known about. Or sometimes they could be saving themselves some headaches. So I thought I'd share three buttons you may not have noticed before that will make your data analysis more efficient.
A chi square test is often applied to two-way tables, like the one below. This table represents a sample of 1,322 individuals. Of these individuals, 687 are male, and 635 are female. Also 143 are union members, 159 are represented by unions, and 1,020 are not affiliated with a union. You might use a chi-square […]

In this 8-part tutorial, you will learn how to get started using Stata for data preparation, analysis, and graphing. This tutorial will give you the skills to start using Stata on your own. You will need a license to Stata and to have it installed before you begin.
I want to do a GLM (repeated measures ANOVA) with the valence of some actions of my test-subjects (valence = desirability of actions) as a within-subject factor. My subjects have to rate a number of actions/behaviours in a pre-set list of 20 actions from ‘very likely to do’ to ‘will never do this’ on a scale from 1 to 7,..
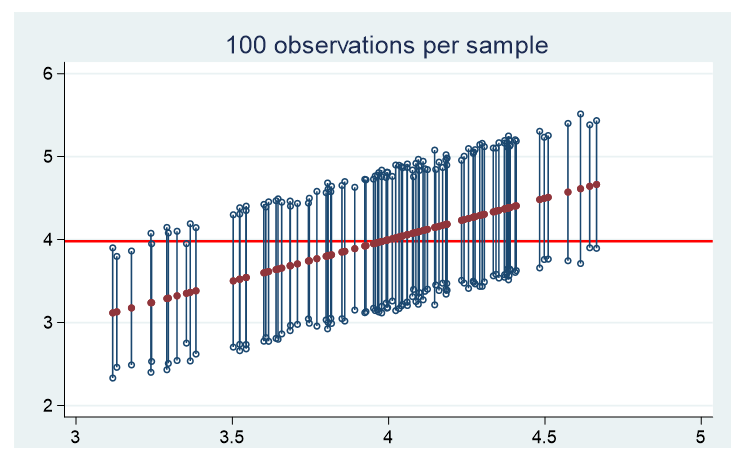
Spoiler alert, real data are seldom normally distributed. How does the population distribution influence the estimate of the population mean and its confidence interval? To figure this out, we randomly draw 100 observations 100 times from three distinct populations and plot the mean and corresponding 95% confidence interval of each sample.

Is it really ok to treat Likert items as continuous? And can you just decide to combine Likert items to make a scale? Likert-type data is extremely common—and so are questions like these about how to analyze it appropriately.
 stat skill-building compass
stat skill-building compass