new blog post: Member Training: The Dark Side of Data Science

Previous Posts
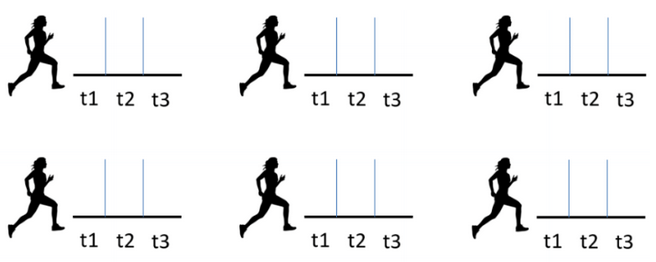
There are many designs that could be considered Repeated Measures design, and they all have one key feature: you measure the outcome variable for each subject on several occasions, treatments, or locations. Understanding this design is important for avoiding analysis mistakes. For example, you can’t treat multiple observations on the same subject as independent observations. […]
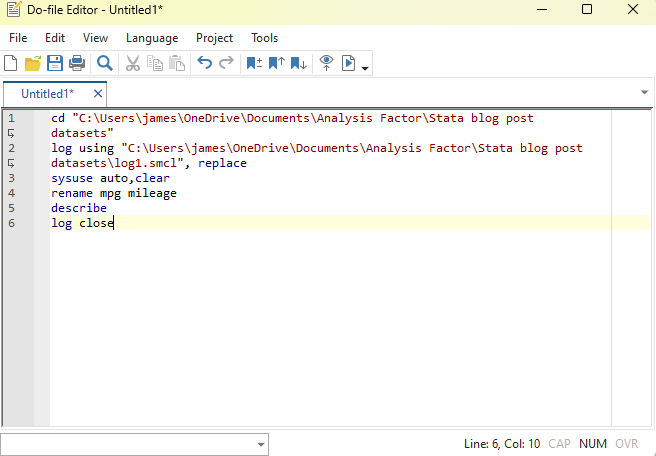
From our first Getting Started with Stata posts, you should be comfortable navigating the windows and menus of Stata. We can now get into programming in Stata with a do-file. Why Do-Files? A do-file is a Stata file that provides a list of commands to run. You can run an entire do-file at once, or […]

Regression is one of the most common analyses in statistics. Most of us learn it in grad school, and we learned it in a specific software. Maybe SPSS, maybe another software package. The thing is, depending on your training and when you did it, there is SO MUCH to know about doing a regression analysis […]
When you draw a graph- either a bar chart, a scatter plot, or even a pie chart, you have the choice of a broad range of colors that you can use. R, for example, has 657 different colors from aliceblue to yellowgreen. SAS has 13 shades of orange, 33 shades of blue, and 47 shades […]
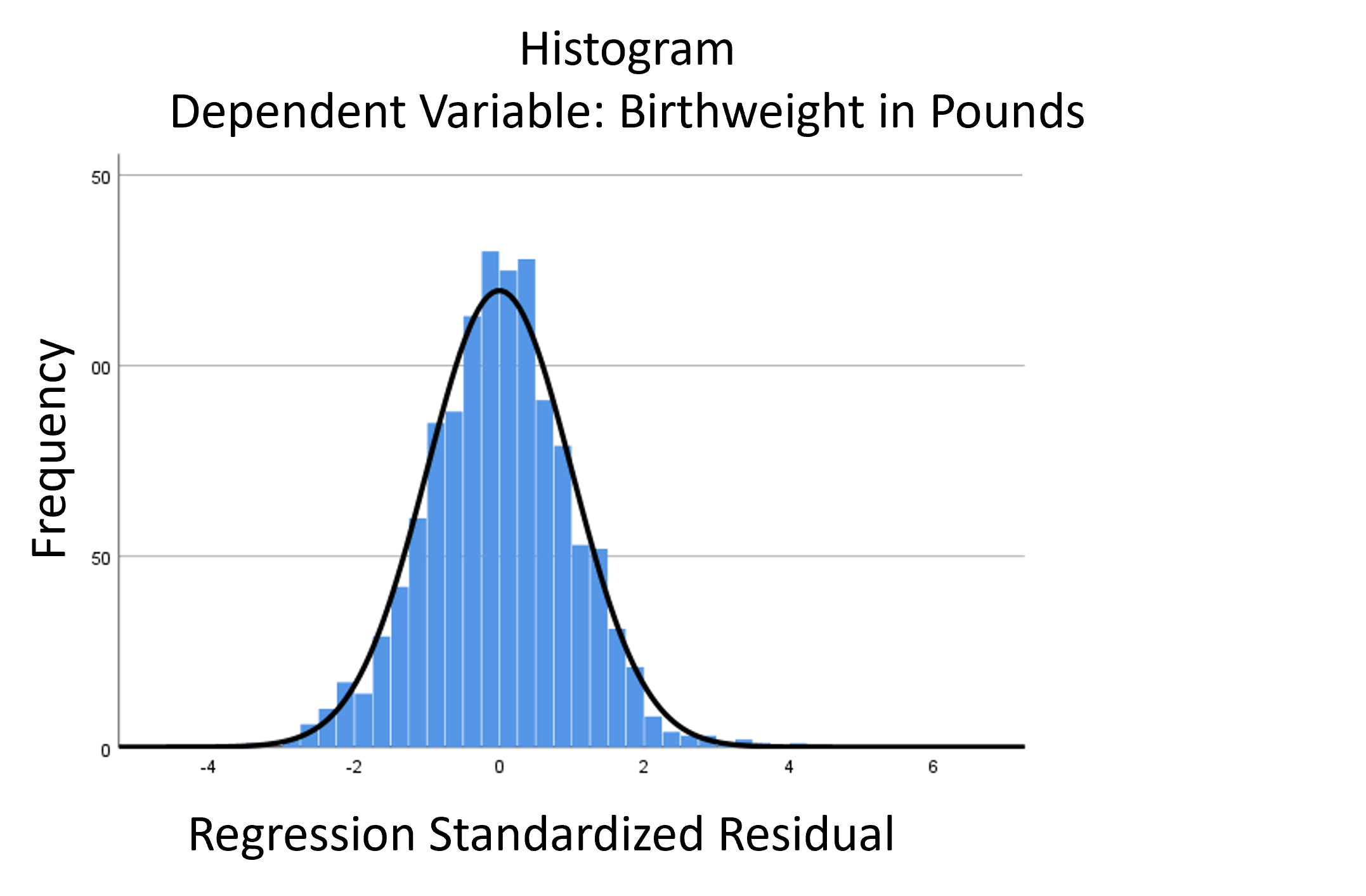
I recently received a great question in a comment about whether the assumptions of normality, constant variance, and independence in linear models are about the residuals or the response variable. The asker had a situation where Y, the response, was not normally distributed, but the residuals were.

The objective for quasi-experimental designs is to establish cause and effect relationships between the dependent and independent variables. However, they have one big challenge in achieving this objective: lack of an established control group.
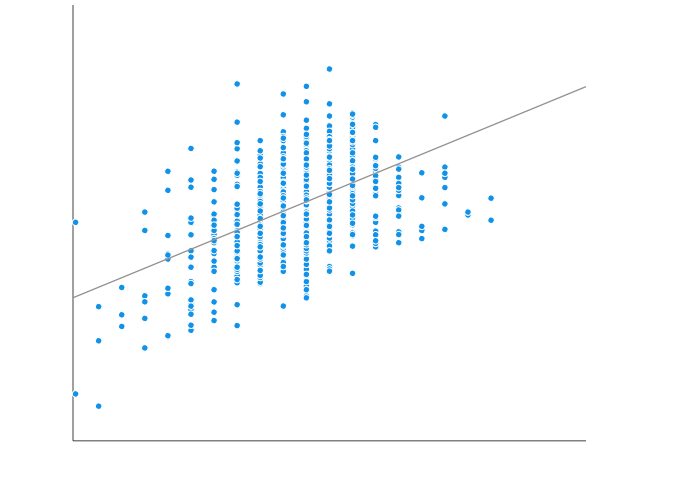
A well-fitting regression model results in predicted values close to the observed data values. The mean model, which uses the mean for every predicted value, generally would be used if there were no useful predictor variables. The fit of a proposed regression model should therefore be better than the fit of the mean model. But […]
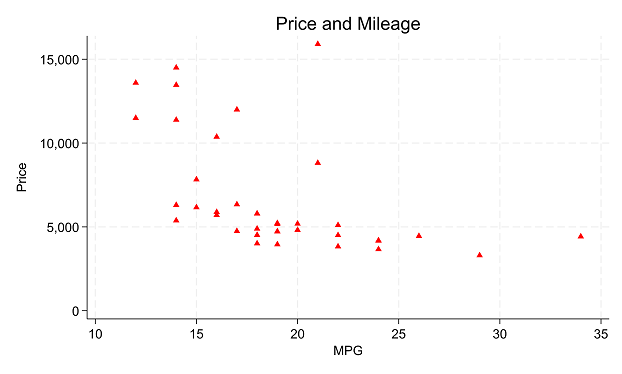
In part 3 of this series, we explored the Stata graphics menu. In this post, let’s look at the Stata Statistics menu. Statistics Menu Let’s use the Statistics menu to see if price varies by car origin (foreign). We are testing whether a continuous variable has a different mean for the two categories of a […]
Do you ever wish your data analysis project were a little more organized?
Tell me if you can relate to this: You love your field of study, you enjoy asking the big questions and discovering answers. But, when it comes to data analysis and statistics you get a little bogged down. You might even feel a bit lost sometimes. And that is hard to admit. Because after all, […]
 stat skill-building compass
stat skill-building compass