by Maike Rahn, PhD
An important question that the consultants at The Analysis Factor are frequently asked is:
What is the difference between a confirmatory and an exploratory factor analysis?
A confirmatory factor analysis assumes that you enter the factor analysis with a firm idea about the number of factors you will encounter, and about which variables will most likely load onto each factor.
Your expectations are usually based on published findings of a factor analysis.
An example is a fatigue scale that has previously been validated. You would like to make sure that the variables in your sample load onto the factors the same way they did in the original research.
In other words, you have very clear expectations about what you will find in your own sample. This means that (more…)
by Maike Rahn, PhD
Rotations
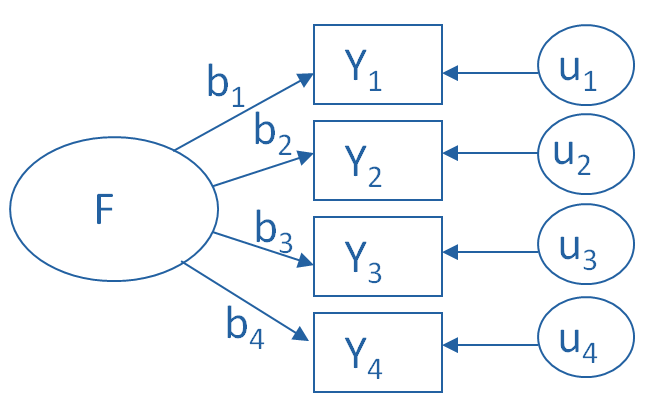
An important feature of factor analysis is that the axes of the factors can be rotated within the multidimensional variable space. What does that mean?
Here is, in simple terms, what a factor analysis program does while determining the best fit between the variables and the latent factors: (more…)
Why use factor analysis?
Factor analysis is a useful tool for investigating variable relationships for complex concepts such as socioeconomic status, dietary patterns, or 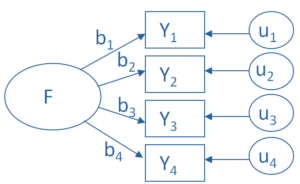 psychological scales.
psychological scales.
It allows researchers to investigate concepts they cannot measure directly. It does this by using a large number of variables to esimate a few interpretable underlying factors.
What is a factor?
The key concept of factor analysis is that multiple observed variables have similar patterns of responses because they are all associated with a latent variable (i.e. not directly measured). (more…)
by Ritu Narayan
Sampling is a critical issue in any research study design. Most of us have grappled with balancing costs, time and of course, statistical power when deciding our sampling strategies.
How do we know when to go for a simple random sample or to go for stratification or for clustering? Let’s talk about stratified sampling here and one research scenario when it is useful.
One Scenario for Stratified Sampling
Suppose you are studying minority groups and their behavior, say Yiddish speakers in the U.S. and their voting. Yiddish speakers are a small subset of the US population, just .6%. (more…)
by Annette Gerritsen, Ph.D.
In an earlier article I discussed how to do a cross-tabulation in SPSS. But what if you do not have a data set with the values of the two variables of interest?
For example, if you do a critical appraisal of a published study and only have proportions and denominators.
In this article it will be demonstrated how SPSS can come up with a cross table and do a Chi-square test in both situations. And you will see that the results are exactly the same.
‘Normal’ dataset
If you want to test if there is an association between two nominal variables, you do a Chi-square test.
In SPSS you just indicate that one variable (the independent one) should come in the row, (more…)
Censored data are inherent in any analysis, like Event History or Survival Analysis, in which the outcome measures the Time to Event TTE. Censoring occurs when the event doesn’t occur for an observed individual during the time we observe them.
Despite the name, the event of “survival” could be any categorical event that you would like to describe the mean or median TTE. To take the censoring into account, though, you need to make sure your data are set up correctly.
Here is a simple example, for a data set that measures days after surgery until an (more…)