December 2017 | Issue 173 | | | |
Can you believe it is already December? This year flew by for us. We hope it has been a great 2017 for you!Â
Â
We've got some great new workshops planned for 2018, starting in January with a brand new, soup-to-nuts workshop on a fundamental topic: Linear Models.
Like all of our statistics training workshops, a key feature is the workshop will be software-agnostic. The teaching webinars focus on concepts, steps, and interpretation. Included in the workshop pack is a separate set of video tutorials on how to implement in R, SPSS, SAS, and Stata.
Now Jeff has written an article that tackles a challenge that most of us have felt: explaining a tricky statistical result to an untrained audience. I hope you
enjoy.
Happy analyzing,
Karen
| | | | Statistically Speaking
Webinar: | | | | | How do you like this newsletter layout? | | | | Using Marginal Means to Explain an Interaction to a Non-Statistical Audience | | | | Even with a few years of experience, interpreting the coefficients of interactions in a regression table can take some time to figure out. Trying to explain the results shown in a regression table to a group of non-statistically inclined people is a daunting task. For example, you are going to speak to a group of dietitians. They are interested in knowing if there is a difference in the mean BMI based on gender and three types of body frames. If there is a difference, the dietitians might decide to take a different weight loss treatment approach for each
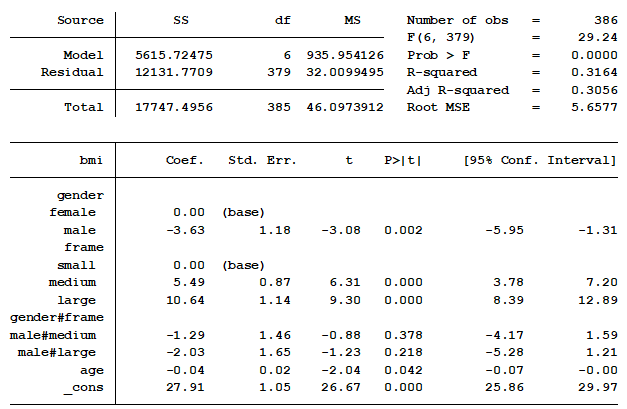
group. For our model, BMI is our outcome variable. It needs to be a linear regression model because BMI is a continuous variable. To determine if there is a statistical difference between groups and gender we need to include an interaction between the two categorical variables. The regression table below is a typical example of what all statistical software produce. This one is generated by Stata. | | | | You show this table in your PowerPoint presentation because you know your audience is
expecting some statistics, though they don’t really understand them. You begin by explaining that the constant (_cons) represents the mean BMI of small frame women. You have now lost half of your audience because they have no idea why the constant represents small frame women. By the time you start explaining the interaction you have lost 95% of your audience. You realize that this approach was a bad idea. Would there have been a better way to present these results? First rule, always know your audience. How statistically knowledgeable are they? What are they interested in knowing? My approach would have been to start by showing them the
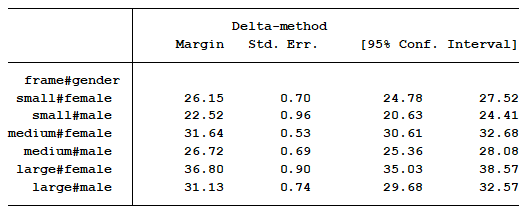
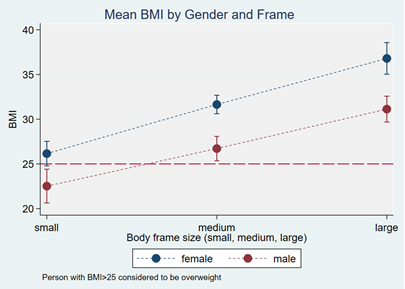
marginal means for each of the six groups. This table is easy to understand and to interpret. This is not the default output from the statistical software, but it’s not hard to obtain. Note that I excluded the t-score and p-values. That information is not important because it tells us whether the marginal mean of each category is significantly different from zero. | | | | I would then graph the marginal means because it’s easier to visualize the results. | |
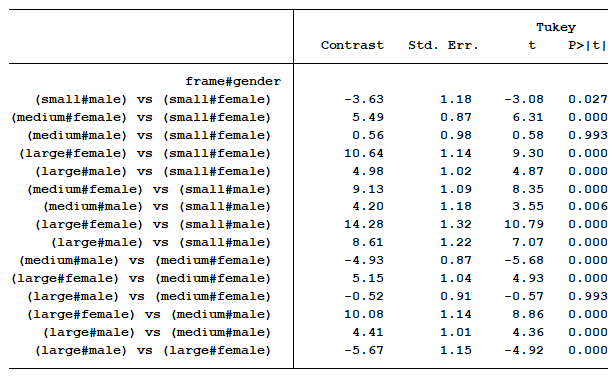
| | As a finale, I would then address the question the dietitians all had. Are there differences among the six groups? I answer that question by running a pairwise comparison. | | | | I can now easily explain to them that there is a statistical difference between every combination of sex and gender with regards to mean BMI except for two situations.  Furthermore, the differences in means for each comparison clearly communicate the size of each
effect. For example, we can see the size of the gender effect is -3.63 for people with small frames, -4.93 for people with medium frames, and -5.67 for people with large frames. You know and can report that these contrasts are not significantly different from each other because that is what the interaction terms in your original regression model measured. You can have that information ready for any members of the audience who are interested in that specific test and who will understand the output (Appendices are a great place for this). No one is left scratching their head.
While this example showed a linear model, this exact approach is especially useful for understanding the effects of categorical variables with interactions in generalized linear models. In that situation, though, you have to make sure you’re not using
p-values on marginal means that have been back-transformed. | | | | Want to see more from Jeff?
Join his January workshop on Linear Models: | | | | | References and Further Reading | | | | Share the love. Forward this newsletter to friends, fans, and
colleagues who might be interested. Your recommendation is how we grow. Get this email from a friend, colleague, or secret admirer of all things statistics? Click here to subscribe. | | | | |